Phonology: case studies
By Scott Myers and Megan Crowhurst
Department of Linguistics at the University of Texas
Initial data and acoustic correlates
As an initial approach to the distribution of dorsal stops in Turkish, let us consider the sets of words in (2), that illustrate the regular distribution of velars [k g] and palatals [c ɟ] in word-initial position. In (2a) we see that palatals can precede any of the front vowels [i e y ø], while figure (2b) shows that velars may precede any of the back vowels, [ɨ a u o].
| (2) | Word-initial dorsals |
| a. | Palatals | |||||
| cir | 'dirt' | ɟij | 'wear!' | |||
| cyt͡ʃyc | 'small' | ɟylj | 'laugh!' | |||
| celj | 'bald' | ɟelj | 'come!' | |||
| cør | 'blind' | ɟøys | 'chest!' | |||
| b. | Velars | |||||
| kol | 'arm' | gol | 'goal' | |||
| kul | 'slave' | gaz | 'gas' | |||
| kɨr | 'meadows' | |||||
| kap | 'container' | |||||
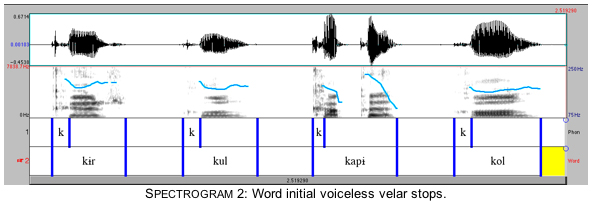
Phonetically, palatal and velar stops are distinguished by differences in the relative intensity and frequency of the release following the closure. Spectrogram 1 and Spectrogram 2 show voiceless palatal and velar stops (respectively) in prevocalic position. The acoustic energy is more intense for the palatals (Spectrogram 1) than for the corresponding velars (Spectrogram 2). Also, the energy in the release of a palatal stop is distributed over the mid to upper frequencies, while energy in the velar release is much more narrowly distributed, tending to be concentrated in the lower frequency range. The examples in these spectrograms show word initial dorsal stops immediately before a vowel. Only the release, and not the stop closure is marked.

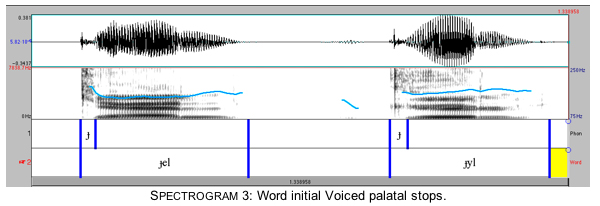
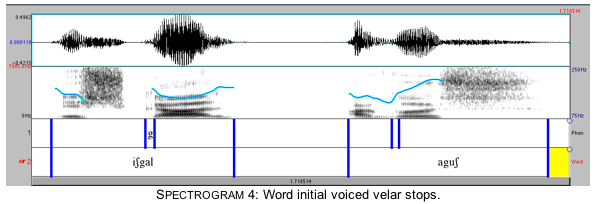
Spectrograms 3 and 4 show that the same is true for voiced palatals and velars, although the duration of the release is shorter for voiced than for voiceless stops. Spectrograms 3 and 4 present two examples of voiced palatal and velar stops. Crosslinguistically, the most common environment for palatals is before the high front unround vowel [i]. The example ɟelj in Spectrogram 3 shows that palatals occur before nonhigh as well as before high vowels, while ɟylj shows that palatals occur before round as well as nonround vowels. Spectrogram 4 shows that the voiced velar occurs before both high and nonhigh, and before round and nonround vowels, as long as they are [+back]. (In examples used for the spectrograms, vowels following dorsal stops are stressed.)
The examples in (2) showed the distribution of word-initial palatal and velar stops before vowels of different backness. The examples in (3) show the "mirror image" distribution for dorsal stops in word-final position: palatals after front vowels, velars following back vowels.
| (3) | Word final dorsals |
| a. | Palatals | |||||
| dic | 'upright' | jyc | 'load' | |||
| tec | 'single' | døc | 'pour' | |||
| b. | Velars | |||||
| ok | 'arrow' | ak | 'white' | |||
| sɨk | 'often' | hukuk | 'law' | |||
| Notice that (3) contains no examples of voiced dorsals in final position. This is due to a process of syllable final devoicing, discussed on another page in this module. Voiced dorsals are less common than voiceless dorsals for this reason, but also because voiced dorsals are often deleted in intervocalic (V__V) position. For these reasons, most examples of [g] and [ɟ] we see will occur either in word initial position or as the second consonant in a consonant cluster. |
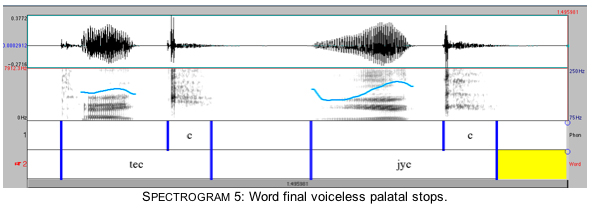
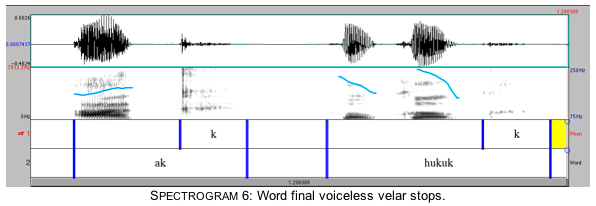
Spectrograms 5 and 6 show that as in the case of prevocalic dorsal stops, the energy in the palatal release is more intense than in the velar release. (In parallel with Spectrograms 3 and 4, Spectrograms 5 and 6 show the dorsal stops after a mid nonround vowel and a high round vowel.)
The data presented in (2) and (3) above suggest a clear correlation between the quality of a dorsal stop (palatal or velar) and the quality of a vowel in its environment. At this point it seems appropriate to affirm that with one or two caveats (involving exceptional cases to be discussed at the end of the section), this correlation is absolute. This being the case, we are ready to propose the interim generalization in (4).
| (4) | Interim generalization 1: Within the class of dorsal stops, velars and palatals are in complementary distribution, with velars co-occurring with back vowels, and palatals with front vowels. |
| An interim generalization is a preliminary generalization that will later be either rejected or refined, when additional data is considered. |
Phonemic analysis: some considerations
To review some basics, in working out the phonemic relationship(s) between sounds in any two categories, sets A and B, there are three possibilities in the simplest cases. These are summarized in (5).
| (5) |
| Distribution | Hypothesis | |
|---|---|---|
| Full contrast | A and B have the same distribution. They occur in all of the same phonological environments. | A and B belong to distinct phoneme classes with no shared allophones. |
| Noncontrastive (complementary distribution) | The distributions of A and B do not overlap. They occur in none of the same phonological environments. | A and B are members (allophones) of a single phoneme, either /A/ or /B/. |
| Partial contrast (neutralization) | A and B have partially overlapping distributions. They share some environments, but in a special context, we find A and not B. | /A/ and /B/ are distinct phonemes, but they share at least one allophone. |
When members of two sound categories (here, palatals and velars) are in complementary distribution, the difference between them is nondistinctive. In this case, we consider seriously the possibility that the most closely related members of each class are allophones of single phonemes, and that the difference between them is due to context. Pairing our stops by voice, we may infer from their distribution that the voiceless set [k c] are allophones of a single phoneme, and so are the voiced set [g ɟ]. In these cases, a single-phoneme hypothesis is especially plausible since the relationship between palatals and velars is "suspicious" in the sense discussed earlier. Based on the information we have so far, however, we cannot tell whether velar allophones are derived from palatal phonemes, as shown in (6a), or whether palatals are instead derived from velars, as in (6b).
| (6) | a. | /cɟ/ | b. | /kg/ | ||
 |
 |
|||||
| [cɟ] | [kg] | [cɟ] | [kg] | |||
How do we determine which scenario we should assume for Turkish? Generally, in cases of complementary distribution, we analyze the contextually restricted allophones as the derived ones. The reasoning that guides this choice is as follows: sound processes operate predictably in specific environments. Therefore, given a set of related allophones, if the distribution of one allophone can be predicted because it occurs in a coherent environment that is easy to state, then this allophone is likely to be the result of such a sound process. Moreover, we value simplicity in analyses. Simpler rules are taken to reflect more natural sound processes. Given a choice between otherwise equivalent analyses, we give priority to the simpler explanation.
The problem we face is that neither set of dorsal allophones appears to be more restricted than the other. Each set is fully predictable depending on context, and the rule needed to derive one set is as simple as the rule required to derive the other. Taking the velars as basic and palatals as derived assumes a rule of Velar Fronting (a type of palatalization), stated in simplified terms in (7a). Conversely, taking the palatals as basic and velars as derived assumes a rule of Palatal Backing in (7b).
| (7) | a. | Velar Fronting: /velars → [palatals] in the context of front vowels. |
| b. | Palatal Backing: /palatals/ → [velars] in the context of back vowels. |
Since the very limited set of data we have seen so far does not clearly favour one approach or the other, we can defer our decision until we have more information.